吊打谷歌!DeepSeek开源首个“奥数金牌”AI
文/第三方供稿2025-11-28 14:36:07来源:第三方供稿
DeepSeek再次归来!
就在昨天晚上,DeepSeek悄悄地上了一个新模型:DeepSeekMath-V2。
这是一个数学方面的模型,也是目前行业首个达到IMO(国际奥林匹克数学竞赛)金牌水平且开源的模型。
奥数金牌 开源双爆
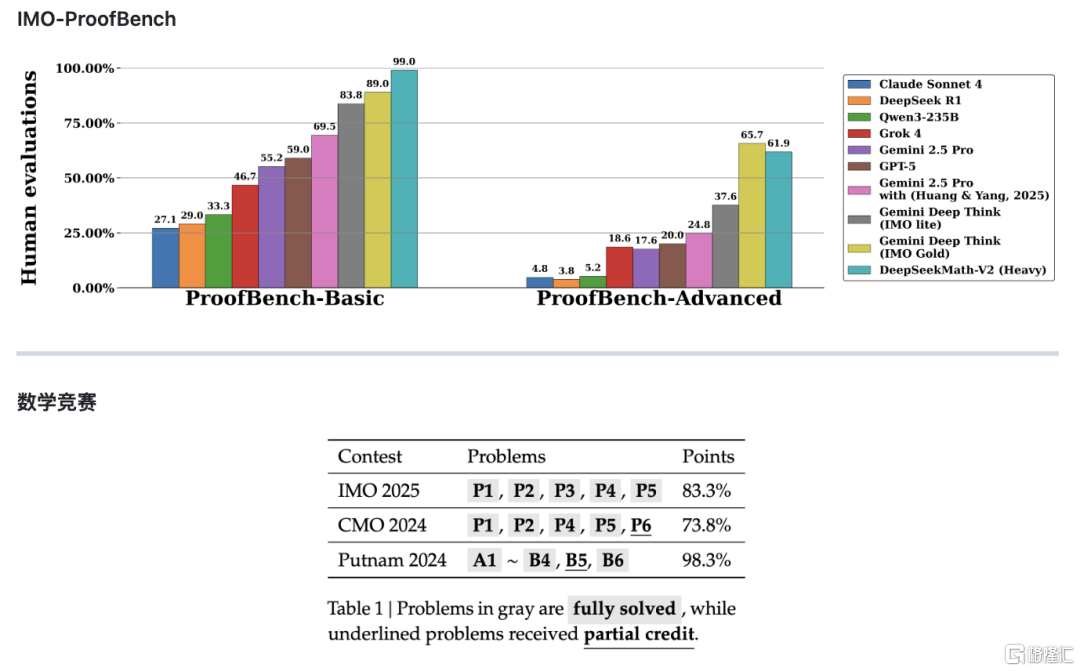
根据同步发布的技术论文《DeepSeek Math-V2:迈向可自验证的数学推理》,该模型在IMO-ProofBench基准及近期数学竞赛中表现优异,部分性能优于谷歌Gemini DeepThink系列。

在Basic基准测试中,DeepSeek-Math-V2得分接近99%,显著高于Gemini Deep Think (IMO Gold)的89%。虽然在Advanced子集上Math-V2得分略低于Gemini Deep Think(61.9% vs 65.7%),但整体表现相当接近。
实验结果显示,该模型在IMO 2025:破解5题(共6题),达到了金牌水平;CMO 2024(中国数学奥林匹克):达到金牌水平;Putnam 2024:得分118接近满分(120分),超越人类参赛者最高分(90分)。
DeepSeek表示,尽管仍有大量工作需要完成,但这些结果表明,自验证数学推理是一个可行的研究方向,可能有助于开发更强大的数学人工智能系统。
推特上,国外开发者直呼这是"惊人的发布",有评论用“鲸鱼归来”形容DeepSeek的回归。网友指出,DeepSeek以10个百分点优势超越谷歌的DeepThink令人意外,并期待其未来推出编程专用模型。
AI数学推理迈入自验证时代
在头部厂商密集“出牌”的11月,DeepSeek的亮相堪称精准卡位。
此前OpenAI发布GPT-5.1、xAI推出Grok 4.1、谷歌Gemini 3系列引爆行业,而Math-V2的横空出世,不仅打破了闭源模型在顶级数学推理领域的垄断,更以Apache 2.0开源许可证向全球开发者开放权重,让每个人都能自由探索、微调这一金牌级模型 。
DeepSeek-Math-V2的发布,是开源社区在AI数学推理领域的一个重要里程碑。它不仅提供了一个性能强大的模型,更重要的是,它提供了一个可供借鉴和复现的训练范式。
DeepSeek-Math-V2 的技术突破可以用一个简单的比喻来理解:它就像是给 AI 配备了一个"内部审查官"。
在传统模型中,AI 生成一个证明后,我们只能通过最终答案或人工检查来判断对错。但 DeepSeek-Math-V2 引入了一套全新的训练机制:
1. 训练一个准确可靠的验证器 (Verifier):这个验证器专门负责检查定理证明的每一步是否严密、是否存在逻辑漏洞。
2. 让生成器学会自我改进:模型在生成证明的过程中,会主动识别和修正自己证明中的问题,而不是生成后就完事了。
3. 持续提升验证能力:随着生成器变得越来越强,验证器也需要跟上。DeepSeek 通过扩展验证计算量,自动标注那些"难以验证"的证明,用这些数据继续训练验证器。
行业正密切关注DeepSeek下一代旗舰模型的发布计划,期待这条“鲸鱼”的下一步动向。