DeepSeek凌晨低调更新,新增“快速模式”与“专家模式”,首次在产品端引入模式分层设计,DeepSeekV4至今仍未揭开神秘面纱
2026/04/08 16:49来源:第三方供稿
DeepSeek凌晨低调更新,上线专家模式,或是V4版本发布前奏!
4月8日凌晨,DeepSeek迎来重要更新,最新版本中,DeepSeek输入框上方新增“快速模式”与“专家模式”,而这是DeepSeek走红以来首次在产品端引入模式分层设计。不过目前新版本还处于灰度测试中,并不是全量版本,可以在对话框里输入“专家模式”,就会自动启用新版本。
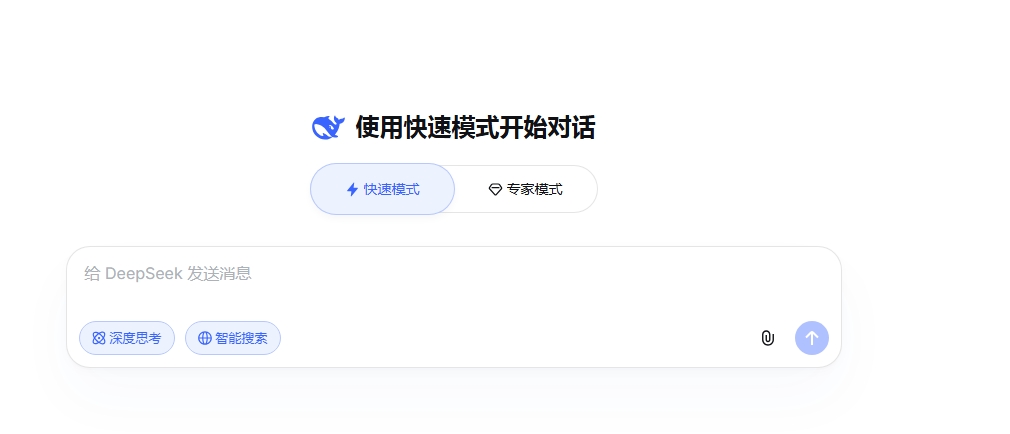
快速模式与专家模式有所区别,快速模式适合日常对话,即时响应,支持图片和文件中的文字识别;专家模式擅长复杂问题,支持深度思考和智能搜索。
值得注意的是,从2026年2月至今,DeepSeek错过了多个发布窗口,至今V4仍未揭开神秘面纱。业内猜测这次对话界面更新或许是V4版本发布的前奏。
3月底,DeepSeek连续三天出现服务中断的意外状况。3月29日至31日,DeepSeek旗下服务连续三天出现不同程度异常,涉及网页对话、App及API等。当时,多名国产模型供应商人士推断此次只有DeepSeek面向C端的产品服务中断,或与模型迭代过程中进行灰度测试有关。有技术社区负责人认为,DeepSeek已经为测试V4准备好了相关基础设施。
至于DeepSeekV4,外界目前尚不得而知,不过或可以从此前梁文锋的论文方向中窥探一二。
1月12日,DeepSeek发布新论文《Conditional Memory via Scalable Lookup: A New Axis of Sparsity for Large Language Models》(基于可扩展查找的条件记忆:大型语言模型稀疏性的新维度)。该论文为北京大学与DeepSeek共同完成,合著作者署名中出现梁文锋。论文提出条件记忆(conditional memory),通过引入可扩展的查找记忆结构,在等参数、等算力条件下显著提升模型在知识调用、推理、代码、数学等任务上的表现。同时,DeepSeek开源相关记忆模块Engram。
这项研究直指当前Transformer 架构的一个痛点:大模型虽然通过 MoE 实现了“条件计算”,但缺乏原生的“条件记忆”。现在的模型记东西太笨,只能靠计算来模拟检索。DeepSeek提出的 Engram 模块,要给大模型装上一个外挂式的“硬盘”,让它能像查字典一样,以 O(1) 的时间复杂度调取知识,而不是靠算力硬抗。
此外,在元旦发布的《mHC:流形约束超连接》中,梁文锋和他的团队解决的是另一个问题——超大规模模型的训练稳定性。随着模型越来越大,传统的残差连接开始失效,训练容易崩溃。DeepSeek 用一套数学方法,把神经网络的连接方式约束在特定的流形空间里,恢复了信息传递的稳定性。
中信证券在最近的研报中指出,DeepSeek V4.0等新一代模型有望将Engram融入已成熟的DSA MoE架构,通过分层存储关键常用信息实现Transformer架构中注意力层计算量的指数级下降,进而实现超长上下文处理,提升模型效率的同时精进代码、Agent能力,补齐多模态短板。
中信证券认为,DeepSeek下一代新模型有望延续高性价比开源模型路线,带来模型原厂、AI应用、AI 基础设施方向的新投资机遇。